The First Thing I Install in Every Claude Code Project

I try a lot of workflows. I keep up with the Ralph loops and the spec-driven setups and whatever else is making the rounds, and I genuinely try them, but I keep coming back to a small set of things that just work. The one I now install before I write a single line in a new project is a Claude Code plugin I built called codebase-mapper. For me it’s the single most game-changing thing in my whole setup, and I don’t say that lightly.
The problem it fixes is boring and constant. Claude Code kept reinventing the wheel. Same project, new session, and it would go re-figure-out how to run Docker here, or re-derive the same convention it already followed yesterday, or wander off and re-read half the codebase just to answer a question it should have known cold. Every fresh session started blind.
The obvious fix is to write it all down in CLAUDE.md. I did. It doesn’t hold. Claude keeps forgetting to read it, and even when it does, it isn’t consistent about it. A file that sits there hoping to get opened is not a system you can rely on. And it’s not just CLAUDE.md: even with a memory system running alongside it, the same forgetting creeps back in. The bigger and gnarlier the codebase, the worse it gets, exactly where you most need Claude to already know its way around instead of rediscovering the layout every single session.
What It Actually Does
When you run it, codebase-mapper reads your actual code and writes a small set of Markdown docs under .claude/.codebase-info/: a compact INDEX.md hub, plus the detailed docs the project warrants. A project with no database gets no database.md. A project with some big custom thing none of those cover gets a doc of its own. In a typical project it looks like this:
.claude/.codebase-info/
├── INDEX.md # the compact hub, injected on every prompt
├── architecture.md
├── directory-structure.md
├── entry-points.md
├── modules.md
├── patterns.md # the non-obvious conventions worth knowing
├── coding-style.md
├── database.md # only if the project actually has one
├── docker.md # only if the project actually has one
└── onboarding.mdINDEX.md is the hub. The detailed docs just sit there and get read on demand, only when a task actually touches them.
Then comes the part that makes it stick. A bundled hook fires on every single prompt and re-injects that INDEX.md hub straight into context, along with a short instruction telling Claude to name which doc it’s about to read and read it before it starts poking around.
That’s the whole trick, and it’s worth being precise about why it’s per-prompt and not once-per-session. A once-per-session injection gets buried as the conversation grows, and Claude quietly stops consulting it. Re-injecting every turn keeps the map in front of the model the whole way through, even three hours deep. The hook doesn’t touch your CLAUDE.md, and it stays completely silent in projects that don’t have a map.
A second skill keeps the docs current as the code changes, adding and pruning docs as the project grows. So the map maintains itself instead of going stale the week after you write it. On an existing project the first mapping takes a while, but after that it just keeps up.
And it’s not a dumb find-and-replace pass. When I actually change the code, the maintenance step does a real documentation check: here it notices a new examples/ folder, updates the one doc that enumerates them (directory-structure.md), and then reasons that nothing else moved, so the rest of the map stays untouched and accurate.

The flip side is just as important. When a turn made no code changes at all, it doesn’t invent busywork. It says so and stops: “No code changes were made, so documentation review is not applicable.” That restraint is what keeps the map from churning. An instruction injected at the start of the turn plus a reminder fired at the end (thank you, hooks again) is what enforces both halves of this: the map gets updated when it should, and left alone when it shouldn’t.

The Honest Trade-Off
Here’s the part I want to be straight about, because it’s the first objection everyone has, including me: you are spending tokens on every turn. That map injection is not free. It rides along with every prompt whether you need it that turn or not.

But look at what you’re trading it against. Without the map, Claude fills its own context with code: grepping around, opening a dozen files, reconstructing the layout from scratch, and doing it again next session because none of it stuck. A couple thousand tokens of a clean, current map is a bargain next to Claude reading ten files to answer something the map already states in two lines. The fixed little cost buys you out of a large, repeated, unpredictable one.
And the tokens are only half of it. The other half is consistency. The map is there every turn by construction, so Claude actually consults it every turn. That reliability is the thing CLAUDE.md could never give me.
It Holds Up Across Very Different Projects
This isn’t a clean-demo thing. I’ve had it running across projects that look nothing alike: a tiny numpy genetic-programming engine, a music-notation app full of VexFlow rendering, and a big document-processing codebase with a whole custom doc just for its filtering logic. The map shape adapts to each one. The small library gets a handful of docs; the big one gets fifteen, including ones the generic set would never think to make.
The payoff shows up the same way everywhere. Claude opens a session by saying which doc it’s going to read, reads it, and gets to work oriented. And my favorite tell, the one that proves the trade-off is real: a lot of the time it now says some version of “I already have what I need from the loaded docs, no need to re-read” and then just does the work. That sentence is the whole point. That’s a session that didn’t burn its context re-exploring the codebase.
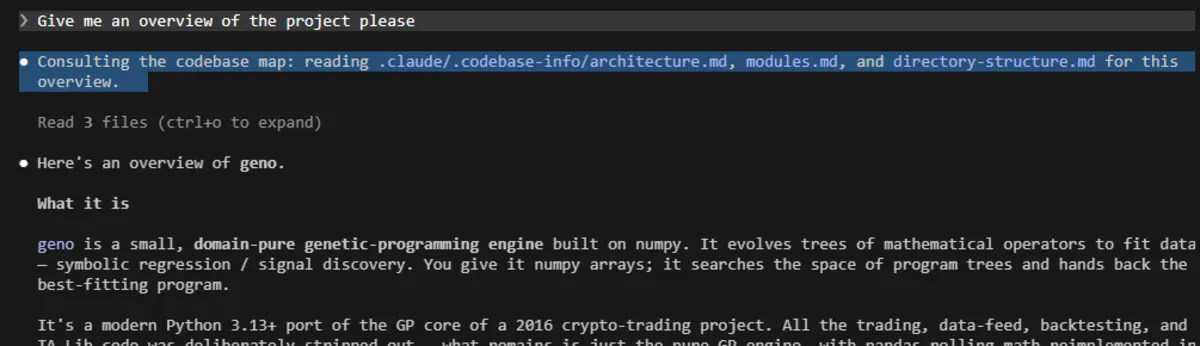
Here’s the behavior in the wild. I ask for a plain overview of the project, and the very first thing Claude does is consult the map: “reading architecture.md, modules.md, and directory-structure.md for this overview.” It didn’t grep. It didn’t open ten files. It read the three docs that already had the answer and gave me a clean summary of the engine. And the part I want to stress: the hook is what forces this, not goodwill. It happens regardless of what’s in CLAUDE.md. The injected instruction rides in on the prompt itself, so Claude orients off the map before it does anything else, every time, whether or not it would have remembered to on its own.
Where to Get It
codebase-mapper lives in my Eigenwise Toolshed marketplace for Claude Code, and it’s MIT-licensed. Installing it is two lines:
/plugin marketplace add Eigenwise/eigenwise-toolshed
/plugin install codebase-mapper@eigenwise-toolshedThen tell Claude to map the codebase (or run /codebase-mapper:map-codebase) and it builds the map from your actual code. After that the hook takes over and a second skill keeps it current, so you mostly forget it’s there.
It grew out of a smaller plugin in the same marketplace called live-rules, which is just one hook that injects a Markdown file on every prompt. You can actually rebuild a basic version of the codebase map with nothing but live-rules and a single rule that loads your own docs, and the repo walks through exactly how. The full plugin just takes over the part that doesn’t scale: writing those docs in the first place, and keeping them current in every project, forever.
If you only take one idea from this: a per-turn hook beats a file you hope gets read. Map the codebase once, let it maintain itself, and let every session start already knowing where it is.
And if you’re at a company trying to get real value out of your AI stack, this kind of setup is a big part of what I do: the plugins, hooks, and skills that make Claude Code actually productive on your own codebase, instead of a clever demo that never quite lands in real work. If you’d want a hand getting it working, here’s how I work.